
Our Board of Advisors helps substantially to shape the conference and to future proof the discussions there. One of these important influencers is Alan Morrison, which we are proud to have as a regular at the conference since 2018. Today Danilo de Oliveira Pereira got him, to answer on the past, present, and future of Semantic AI.
Danilo: What are the major trends and upcoming developments in Semantic AI?
Alan: John Launchbury of the US Defense Advanced Research Projects Agency (DARPA) identified three waves of AI back in 2017, in a video that's well worth watching.
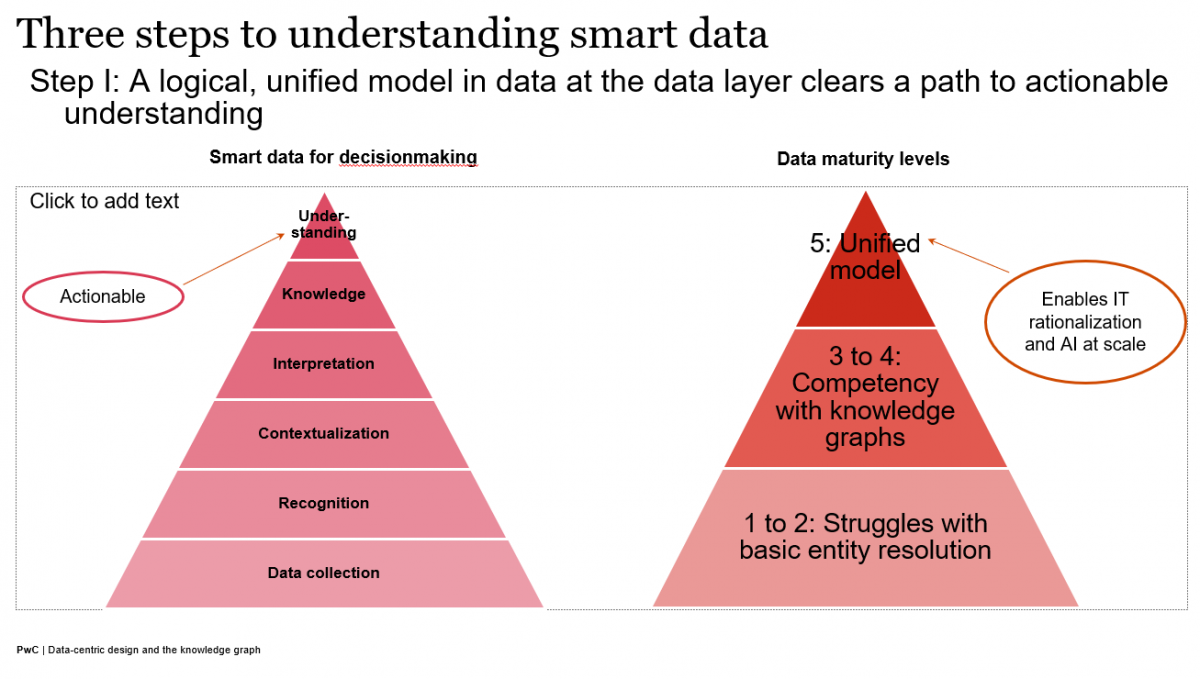
Knowledge representation (dominant during the First Wave of AI) tech helps create context (for the Third Wave that's just getting started) through knowledge graphs. Those are semantic webs of context that consist of what you could call "smart data', which equals the instance data you have plus description or predicate logic that describes and disambiguates that data in the form of Tinker Toy-style graphs. In legacy computing, much of that essential logic is trapped in application code. If you bring the description into the mix at the data layer through the knowledge graph, all of a sudden, you have machine readable context that can be scaled, or "generalized." That context can be the knowledge base for statistical machine learning efforts and can provide a means of reasoning that neural network approaches, for example, lack.

At its most elemental level, such a web of context describes piece by piece how one entity is related to another, such as Ian knows Mary. What's most important here that the Second Wave of AI (the wave of statistical machine learning, including deep learning) has been missing, is the verb in that sentence that describes the relationship between Ian and Mary.
Humans can help machines describe and understand the essential, important relationships between people, places, things, and ideas, and those are represented as interconnected collections of these subjects, verbs, and objects.
Ultimately, those collections of subjects, verbs, and objects or entities and—very importantly, the relationships between them—can constitute a lingua franca between humans and machines, a way to distill and share actionable understanding via knowledge graphs.
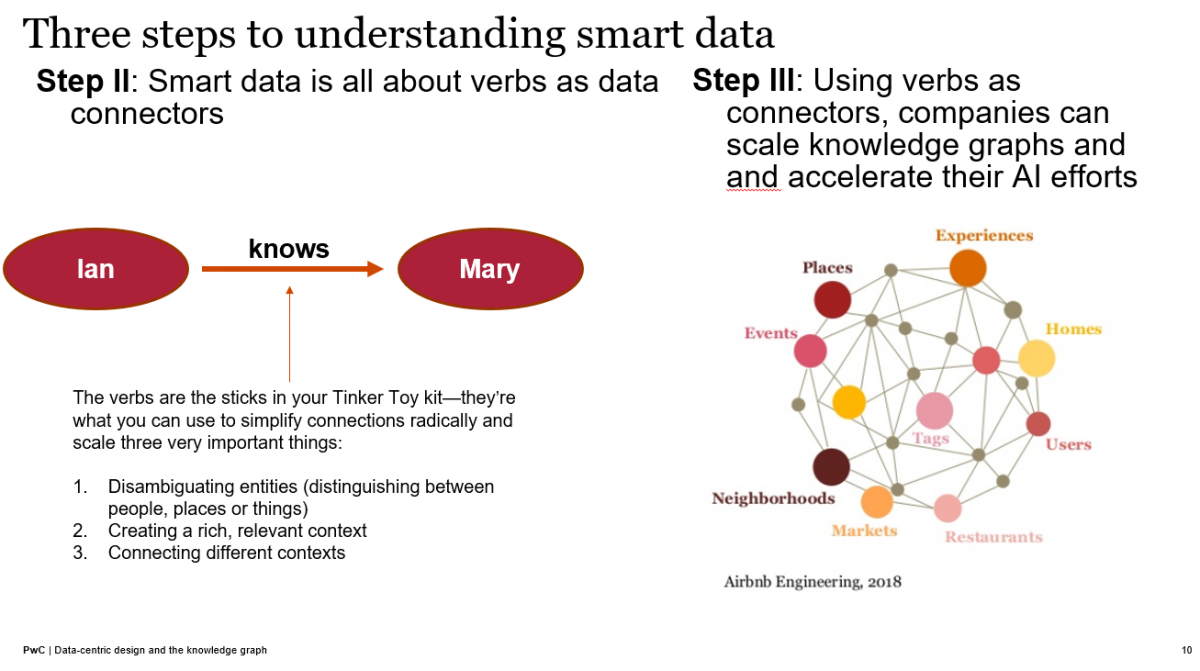
What most don't realize is that most of the data in the data tables that enterprises create and store buries or lacks representations of those essential relationships. Once you make those verbs into the data, machines can "see" and use the context, and even make new inferences on other important relationships that can be added to the mix.
Without context, we can't scale AI. But if we add that context with the help of humans in the loop who understand the relevant business domains, we can create a digital twin of a whole business, whole supply chain, or whole ecosystem by snapping together all these contexts (using standards-based approaches that allow the Tinker Toy connections) to create a fully interoperable picture. That's just one reason why there's so much excitement around knowledge graphs.
Danilo: What are the crucial milestones for such developments?
Alan: The science fiction writer William Gibson famously pointed out in the 1990s that "The future is already here — it's just not very evenly distributed."
The major challenge for knowledge graph adoption is to get beyond mere pockets of adoption. You see very creative and advanced knowledge graph applications, but it's just in pockets. I mentioned during my talk at SEMANTiCS 2018 that nine out of ten of the most value-creating companies in the world are using knowledge graphs. Today, it's still the case that only a small percentage of other companies are using knowledge graphs in an effective way. In addition, some early adopters such as Montefiore Health, a hospital chain that operates in some of the poorest parts of New York City and the Northeastern US, are using knowledge graphs extremely effectively, not only in analytics, but operationally as well.
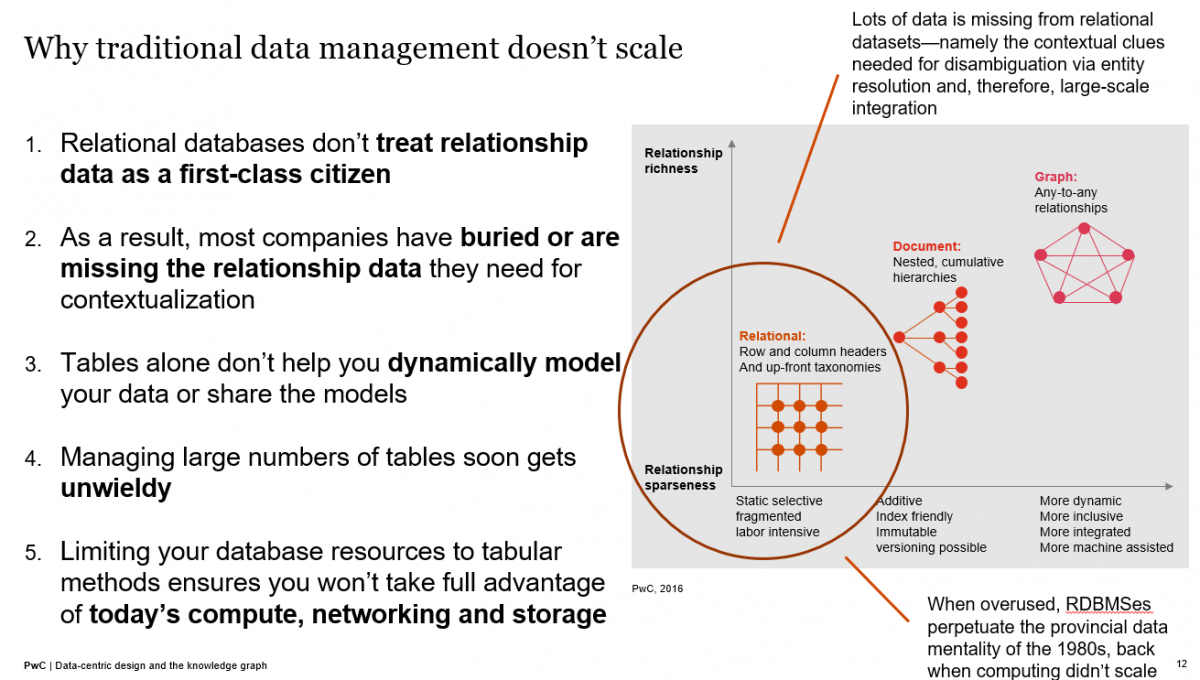
To get beyond just pockets of development, I think enterprise leaders need to be made aware how much near-term value knowledge graphs can deliver as a means of graph-based data management to facilitate GDPR and CCPA compliance and reduce a data-risk footprint that's spiralling out of control. We should bluntly point out that traditional (tabular/relational) data management doesn't scale given today's rates of data growth and the heterogeneity of that data.
In general, we need to get data users and developers to think beyond tables. With graphs, we're not replacing tables—we're weaving together an integration fabric with the help of graphs. The graphs can help us manage any data type.
Somehow, we have to wake up the field of data management and light a fire under leadership to get them to realize that there are better, more efficient ways.
Danilo: What can people expect from your talk at SEMANTiCS?
Alan: I'll be talking about true business transformation using knowledge graphs. Many companies give lip service to "digital transformation" and are investing significant amounts to "transform" themselves. But unless they transform their data architectures and how they use and manage data and harness the description/predicate logic that contextualizes that data, they won't be able to scale their transformation efforts.
It's now 2020, and awareness of these simple facts is still quite low except among the top 20 or 30 internet companies in the world who saw the value of contextualized data early on and mobilized to take advantage of it.
Alan Morrison is a Senior Research Fellow, Emerging Tech for PricewaterhouseCoopers’ Advisory Services in the US. A 19-year veteran of PwC's technology and innovation think tanks in Silicon Valley, Alan identifies emerging technologies on the cusp of adoption, tracks and analyzes how they're being used by large enterprises, and assesses their near-term business impacts on behalf of PwC and its clients.
